
I’ve always found comfort and joy while working in teams, from my time at MITRE building Air Force prototypes as part of an Advanced Development team to my time at Runkeeper building Challenges as part of a multidisciplinary pod. In a team, you have others to help shape designs and to review the work you do. When your team builds something great, you succeed together, and when things don’t go as planned, you learn and grow together. Working as part of a team is perhaps the most rewarding way to build software products – and the extra eyes and perspectives means it often results in the best outcomes, too.
When your team builds something great, you succeed together, and when things don’t go as planned, you learn and grow together.
Which is why, when I joined Ompractice in January 2021, I was intimidated. For the first time in my career, I wasn’t just the only engineer on my team – I was the only engineer at the company. Ompractice hired me as their first full-time developer to rewrite their website from scratch to be more performant, more user-friendly, and more extensible. Here at Ompractice, we have big plans to expand access to yoga, meditation, and other life-changing practices, and a modernized technology platform is the enabler.
But how do you build a website from scratch? Or more specifically, how do you rewrite an established website – one that already has thousands of users actively visiting it? How do you choose the “right” technology stack, how do you balance the time and cost tradeoffs of implementing different tools, and how do you make sure the thing you’re building is actually better than the thing it’s replacing?
Needless to say, I was filled with uncertainty about where to start and anxiety that I would surely miss a critical feature. Not having a team to run things by only made things worse; who would tell me when I was headed in the wrong direction? Who would highlight the tech debt I was introducing along the way?
Nevertheless, despite these worries, our new website launched in March 2022 with no major issues. The new platform loads more quickly, has a streamlined class-enrollment experience, makes it easier for us to modify the schedule, and even alerts us when something’s not right. While there’s still plenty of room for improvement (and there always will be), users have reassured us that “the new site is absolutely fantastic.”
Was rewriting the site as a solo developer quick or easy? Not at all! But rebuilding a software system is an endeavor that many of us have to take on at some point in our engineering careers, so I’ve written up some of the lessons I’ve learned along the way in the hope that others don’t feel so lost and alone when it’s their turn to do the same with a tiny team and a greenfield project. To summarize:
- Don’t Rewrite Your Software System 🙅♀️
- Don’t Do It By Yourself 🙅♀️
- Choose Your Tech Stack and Approach 🤔
- Measure Twice, Cut Once 📏📏✂️
- Double (or Quadruple) Your Time Estimates 📈
- Overly Communicate 💬💬💬
- Establish SDLC from the Get-Go 🚧
- Consider Security 🔐
- Consider Operational Support 🚨
- Test, Test, Test 🧪
- Prepare for the Data Migration 🛢
- Plan and Execute the Cutover 🎬
- Celebrate 🥳
Don’t Rewrite Your Software System 🙅♀️
Firstly, don’t rewrite your software system if you can avoid it! Chances are, the old system might be good enough with just a little thoughtful refactoring and some tactical re-architecture. I can’t overstate how expensive and time-consuming a greenfield rewrite can be, so if the old system works well enough, uses a technology that plenty of developers already know, is understood by the existing developers, and can be improved in a piecemeal fashion, then avoid the full rewrite.
“But the existing codebase is messy,” you might argue. Sure, but most codebases get messy, and often we resort to rewrites without fully understanding the business and technical reasons why the system was built the way it was because reading code is harder than writing it. Per Chesterton’s Fence, don’t destroy or replace something unless you understand it first. Otherwise, you risk missing key considerations and constraints that will result in scope creep and cost increases.
However, sometimes there are good reasons to do a full rewrite, and if that’s the case, at least make sure you understand why you’re rewriting it.
When I joined Ompractice, I gently pushed back on the founders’ demands for a rewrite. I suggested a piecemeal rewrite as an alternative that would result in new features and improvements being delivered sooner than needing to wait for the whole new site to be launched. Luckily, the new founders knew the old system intimately – after all, they built it – and were thus adamant that replacing it with an entirely new system was the way to go. I obliged and spent the next couple of months trying to understand the following:
- 👍 The good: what did they like about the existing web experience? These were the things I’d need to replicate on a new system – AKA parity.
- 👎 The bad: what frustrated them about the existing web experience? These were the things I’d need to avoid recreating.
- 🙈 The ugly: what things were entirely missing from the existing web experience? These were the new features I would prioritize building.
Ultimately, the existing WordPress website was great as a content management system: it allowed anyone in our company to build ad hoc pages without needing to know HTML, JavaScript, or CSS. Accordingly, we actually kept the old WordPress site around after the new site launched and simply stripped away anything that wasn’t static content. Effectively, the old site still exists but has been relegated to only hosting marketing and sales materials.
At the same time, the old WordPress site was a Frankenstein of plugins that got the job done but were hard to finagle into the user experience we desired. Sure, we could host a class schedule, but we were plagued by timezone issues and we never knew which installment of a recurring class someone had registered for. Sure, our system allowed us to create complex membership and class access rules to fit our corporate partners’ needs, but students had to go through an unnecessary checkout flow even when the memberships and classes were free. With these pain points in mind, I prioritized making sure that it would be easy to schedule new classes, that we could easily know which students were signed up for classes during which weeks, and that folks with accounts could sign up for either free memberships or classes with a single click.
Don’t Do It By Yourself 🙅♀️
Okay, so you’ve decided to rewrite your system, but please don’t do it by yourself! Building software is hard, and modern software requires many layers, including but not limited to the user interface, the client business logic, the server business logic, the APIs, the data layers, and the infrastructure. To complicate things further, there are more specific competencies and considerations built into each of these, including scalability, observability, and security. While many software engineers are proficient at several of these layers and some “full-stack engineers” are even proficient at most of these layers, very few engineers are experts at all of these layers (and chances are, you’re not one of these incredibly rare folks).
Unfortunately, having a large team with diverse skill sets supporting your rewrite is easier said than done. If you’re at a place like Ompractice, you’re part of a tiny team with a tight budget and you might have no choice but to approach the rewrite as a solo developer.
Fortunately, being a solo developer doesn’t mean you have to do it “alone.” If you have to rewrite the system by yourself, find people to leverage – either in your company but in a non-engineering role, in your alumni network, or in some other network to which you have access.
Find people to leverage – either in your company but in a non-engineering role, in your alumni network, or in some other network to which you have access.
Even though I was the only engineer at Ompractice for the first three-quarters of the rewrite, I never felt alone. I had the two tech-savvy founders with whom to discuss architectural tradeoffs, salespeople who could use their customer insights to help shape user experience decisions, and part-time designers to help inform the look and feel. Our wonderful Director of Teaching even dedicated countless hours documenting feature requests, advocating for teacher-focused features, and advising on a user experience that would work for teachers and students alike. In summer 2021, we organized a couple of off-sites to get the team together for some collaborative brainstorming that involved sticky notes and sticker dot voting. Sure, I might have been the only one writing code, but the product was still being designed collaboratively.

On the technical front, I was able to leverage the Runkeeper alumni community for advice. In our Slack group, former coworkers described their experiences with technologies I was deciding between, and another coworker even offered architectural suggestions based on his experiences building Runkeeper’s first iteration of training plans.
Lastly, you don’t need to limit your network of help to people you know: at the advice of my COO, I joined the Rands Leadership Slack where I could peruse both past and ongoing discussions about technology choices, frameworks, and architectural patterns. Additionally, I leveraged a fortnightly #cto-coffee meeting to learn from folks at other companies and solicit advice on topics ranging from security to hiring.
This is all to say that if you find yourself rewriting a software system by yourself, leverage the people in both your close and extended networks to help you make decisions in the areas where you need the help.
Choose Your Tech Stack and Approach 🤔
Before you start writing any code, you’ll need to make some technology decisions. These decisions will include things like:
- Choosing frameworks, libraries, and services for parts of the stack (e.g. frontend, backend, hosting, ecommerce, ESP, CMS)
- Selecting one or more data storage technologies (e.g. RDBMS, NoSQL, Object Storage)
- Deciding on API approaches (e.g. GraphQL, REST)
- Picking operational tools and services to support your business’s needs (e.g. analytics, monitoring, alerting)
The Method
Because there’s a lot of decisions to be made, I’ve found it helpful to approach each decision in the following manner:
- What considerations do I need to make with regard to the business’s needs and my own developer experience?
- How important are each of these considerations (e.g. must-have versus nice-to-have)?
- What are the popular options for this particular decision? In other words, what is the solution space?
- How do each of these options score against my weighted considerations?
For example, when I was selecting a frontend web framework to use, I broke my considerations down as follows:
Business Considerations
- 💰 Cost: being a small startup, I was sensitive to cost and only looked at free frameworks with affordable hosting options.
- 🏗 Maintenance: being a team of one, I wanted to select an open-source framework that was maintained by a reliable organization so that I could be confident in its continued maintenance.
User Considerations
- ♿️ Accessibility: at Ompractice, we aim to be as inclusive and accessible as possible, which means I needed to pay attention to how easy it would be to make the web experience accessible for folks who are hard-of-seeing.
- 🌐 Localization: while we mostly serve English-speakers now, we aim to eventually expand to other countries and languages to become the most geographically inclusive yoga and meditation service. Accordingly, I needed to make sure there were solid localization options for whatever technology I selected.
- ⏱ Performance: users get frustrated by slow experiences, so I considered benchmarks like memory allocation and startup time when comparing frameworks like React, Vue, and Angular.
Developer Considerations
- 🤩 Popularity: because we intend to expand our team as the company grows, it was important to choose a frontend technology with a lot of available developers to make future hiring easier; I leveraged StackOverflow’s annual Developer Survey to inform my decisions.
- 📄 Documentation: again, being the only developer, I knew I’d need to rely heavily on existing documentation and knowledge bases to be self-sufficient; I also looked at StackOverflow numbers to see how active the communities were.
- 😌 Familiarity: being already familiar with a technology is a valid consideration for choosing a tech stack; after all, if you already know how to use the language or framework, then you’ll spend less time learning and more time building. Ultimately, I opted to use JavaScript over TypeScript only for the reason that I had too much on my plate to learn another language (although I’ve since begun migrating files to TypeScript post-launch).
Other Considerations
While not directly applicable to my frontend technology choice, some other things I considered for hosting and tooling decisions included privacy, security, and compliance, particularly because we actively partner with health providers and government organizations (like the Department of Veterans Affairs), which both require extra sensitivity around user data.
The Timing
While these technology decisions were all important, they fortunately did not need to be made all at once. I prioritized selecting frontend and backend frameworks and a database first so that I could jump into writing code sooner than later. A few months into development, I looked into hosting options, and a few months later I made decisions on operational tools. By staggering the decisions I needed to make, I avoided burning myself out too much at any point in time and gave myself time to learn and improve from past decisions.
Did I always make the right choices? Of course not. For example, after selecting to use React, I naively started my frontend project as a CRA project before realizing I ought to migrate to a framework like Next.js or Gatsby to better leverage SSG and SSR capabilities that would benefit page load times and thus SEO. This particular poor decision ended up adding two additional weeks of development to my timelines.
Measure Twice, Cut Once 📏📏✂️
When you have a huge development project in front of you, it’s tempting to jump right in because the sooner you start, the sooner you finish, right? However, rushing in too quickly without first ironing out what you are building will result in wasted effort and time as you build the wrong thing in the wrong way. So, first spend some time both understanding and confirming requirements.
Understanding requirements is pretty straightforward: this will involve talking to your stakeholders (e.g. your product manager, your boss, your end users, etc) to understand what their most pressing problems are and what kinds of experiences work well (and don’t work well) for them. If you have customer support tooling in place, also stay on top of the requests and questions coming in: what kinds of problems are your end users facing? What are the frequent pain points they keep hitting? These will likely inform what you build and how you build it.
However, having conversations with stakeholders and listening to users isn’t enough; you’ll want to confirm that you’ve understood the requirements correctly. In my case, I approached confirming requirements by:
- ✅ Listing functional capabilities: by listing out what I understood to be the capabilities, it was easier for others to let me know what I had missed.
- 🎨 Mocking up user flows: I used a tool called Whimsical to ensure that my vision of the user interface and flows matched my founders’. The mocks were extremely low fidelity but communicated the gist of what I’d be building.
- 🗺 Defining API endpoints: my UI mocks helped dictate how I’d need data and business logic exposed to the fronted; I used a simple spreadsheet for this and included columns for each HTTP method and for each end user type (e.g. student versus teacher versus administrator) in order to better capture behavior and access control considerations.
- 🛢 Drafting a database schema: I used dbdiagram.io to build an entity-relationship diagram for the new database, and I reviewed our existing WordPress tables to ensure I covered all of the critical business data that I’d need to migrate.



Did everything get built exactly as specified? Not at all! But by taking these deliberate steps to capture and document requirements upfront, I could proceed into writing code with more certainty that I was going in the right direction and that my founders had clear visibility into what that direction was.
Double (or Quadruple) Your Time Estimates 📈
I was lucky that my COO understood that building software “takes as long as it takes.” However, even if you have a boss who is as accommodating as mine is, you’ll still want to set delivery expectations as clearly as possible, and that means taking your best guess at time estimates.
As we all probably know, engineering estimates are unreliable and more magic hand-waving than science. Nonetheless, here are some tips:
- Create a running list of things that need to get done so you don’t forget.
- Have a PM and a designer? Double your time estimates.
- Also wearing a PM hat and making substantial product decisions? Double your time estimates again.
- Caveat the hell out of your estimates and track and communicate risks.
Why are time estimates so important even if software takes as long as it takes to build? Well, by being transparent about how long you think something will take, you empower your stakeholders to change the scope to reduce or increase that time. If it’s more important for the software to go out sooner than later, then maybe you will all agree to cut out features X, Y, and Z from the initial launch. However, if those features are critical, then you at least are all on the same page that the additional time is worth it.
For example, it was very important to our Ompractice founders that we launch with new capabilities for our teachers to let them see their student rosters and documented policies all in one place. Accordingly, they never wavered on this feature even when it would add a month to our launch timeline. However, we didn’t need all the teacher features all at once, and so we punted on a few teacher capabilities knowing we could add them easily after the site went live.
Overly Communicate 💬💬💬
If you are like me and one of the only engineers at your company, then you may be surrounded by folks who think what you do is magic. But if no one understands what you’re doing, how do you communicate that progress is being made? How do you demonstrate that you are in fact working hard even if “The Big Thing” isn’t ready yet?
Simple: teach your teammates about engineering! Try to explain what you’re doing and why in layman’s terms as often as you can so people can follow along on your progress.
In my daily Slack updates, I tried to add context where possible, e.g.:

I also gave an hour-long Zoom presentation to my colleagues and our teachers called “How Does The Internet Work?,” relying heavily on a restaurant analogy and lots of visuals.
Did this turn my coworkers into engineers? Of course not! But it hopefully gave them more insight into what was being built long before it actually went live.
Establish SDLC from the Get-Go 🚧
While you don’t want to overengineer your systems too much upfront, it is still beneficial to get some process and tooling in place early on. Getting software development lifecycle (SDLC) elements in place early allows you to:
- Benefit from the quality and documentation-generating effects upfront
- Get in the habit of consistent, good practices before the team and product grows
- Avoid the thrash and confusion of retroactively changing process
In particular, I’d recommend establishing source code management practices, differentiated environments, and test infrastructure well before launch.
Source Code Management
If you’re working on a greenfield project, there’s no reason not to establish a source code repository upfront. Even if you’re the only developer, using a tool like Git will still benefit you by giving you a way to track down when changes were previously introduced and, if you’re decent at writing commit messages, give you some context on why.
Furthermore, I’d encourage folks to adopt a branching and pull request strategy upfront. Not only will this get you in the habit of organizing your changes into smaller, discrete chunks of work, but it doubles as documentation when you bring in your second and third engineers. For the new Ompractice website, I established a pretty simply branching strategy from day one, created a simple and straightforward pull request template to cover scope and testing details, and opened forty-one pull requests before another engineer ever joined our team. Even as a solo developer, I often found myself referring back to the PRs to refresh on the context of my past decisions.
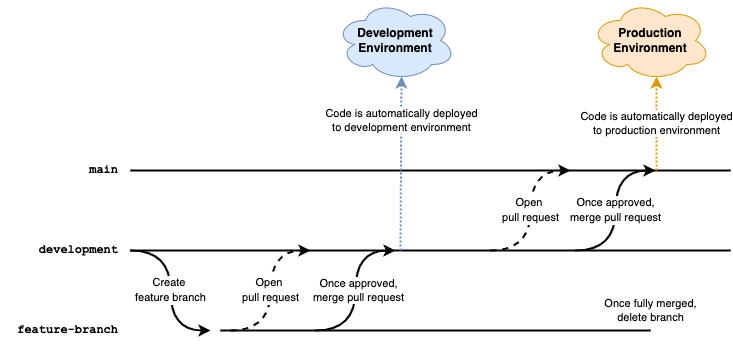
Environments
It goes without saying that you’ll want a local environment to build and test with – that’s how most of us write code in the first place. However, I’d go further to argue that not only do you need your own working local environment but you ought to thoroughly document the setup steps so that when you do hire that second engineer (or when you need to switch computers because your old laptop died 😅), the process will be less painful. READMEs colocated with the source code are a great way to approach this because they’ll be easy to find.
Furthermore, by writing these setup steps the first time you set up your environment, you’ll be less likely to miss something and it will be easier to update as you incrementally add more complexity to the setup overtime. For example, while my initial setup docs focused on getting a database, superuser, Django server, and React app up and running, I eventually added details about hooking up external systems like Shopify, SendGrid, and MailChimp.
In addition to your local environment, you’ll obviously want a production environment. However, because local environments are often incredibly different than hosted ones, it usually makes sense to also set up a hosted development, test, or staging environment as well. Basically, whatever you plan to do for your production environment, set up an identical (or almost identical) environment where you can test your changes before they go live. Firsthand, I benefitted from such a test environment when it allowed me to catch CORS and cookie-related issues that were difficult to replicate locally.
Testing
Lastly, if you’re the only developer, you’re likely the only dedicated tester, too. Save yourself time and reduce headaches by getting some tests scripted upfront. At ASICS, I saw the never-ending struggle of trying to retroactively add tests to code that was always changing and promised myself to try and avoid that frustration again. Accordingly, I made it a point to write tests for every API endpoint that I added before moving onto new chunks of work. In particular, I made sure that these tests covered:
- 🔐 Access control: above all else, I was most paranoid about having endpoints accidentally expose sensitive data to the wrong parties, so I wrote hundreds of access control tests before the site launched to verify the access and content differences between administrators, teachers, students, and unauthenticated users.
- 😄 Happy path: naturally, you want your API to return status codes and response bodies for valid, expected inputs, and so I wrote tests around different happy path permutations.
- ⛔️ Invalid data: lastly, you want your system to handle bad data gracefully, and so I tried to include various tests to ensure that exceptions were handled without crashing the server and that the expected status codes and error messages were returned.
Consider Security 🔐
If you are like me, security concerns are what keep you up at night, so in addition to the access control tests, I spent a significant amount of time researching security best practices. However, security is a huge and complicated domain, so unless you’ve already spent years fully focused in this area, chances are you’re not an expert. As a security-aware but not security-focused engineer, this is how I approached securing the new system I was building:
- Research: while you may never be a cyber security expert, it’s still important to get a foundational understanding of how security impacts the work that you do. When implementing our authentication and authorization mechanisms, I spent several days reading up on different identity management services (like Auth0, Okta, and Firebase) as well as topics like JWTs (including criticisms and vulnerabilities), frontend token storage, multifactor authentication, credential stuffing attacks, and password hashing best practices.
- Leverage baked-in security: chances are, you’re using well-established frameworks, libraries, and services that already have some security features baked in by folks with a deeper understanding of the space than you have. Accordingly, leverage this. For example, I spent time learning about and leveraging the security affordances that Django already has baked into its framework.
- Get external help: as mentioned earlier, augment your own abilities with those of folks in your network. I solicited advice from folks in the Rands #cto-coffee meeting and received recommendations on specific pen-testers as well as advice on different best practices resources.
- Follow best practices: one of the resources #cto-coffee folks recommended reviewing was the OWASP Top Ten, which documents some of the most common security vulnerabilities with common mitigation steps.
Consider Operational Support 🚨
By this point, you’ve hopefully grasped the scope and requirements of what you should be building, made tech stack decisions particular to your business’s needs, planned out your architecture, adopted SDLC processes and tools, baked security considerations into most of your technical decision making, and started writing the code to power your new system.
But you’re not done yet! How will you know if something is broken? How will customers reach out if there are issues? Because – and trust me on this – even if you’re the best developer in the world, there will be issues.
This is why, ten months into development, I began to evaluate and integrate different tools for the following sorts of capabilities:
- 🪵 Logging: logging API requests and system behavior is incredibly useful for troubleshooting production issues and tracking down bugs.
- ⚠️ Error monitoring: noticing errors and seeing their stack traces not only allows you to be aware there is a problem but gives you insight into how to fix it.
- 🚦 Traffic monitoring: understanding the amount and kinds of traffic that hit your system can help ensure you build scalable software that can accommodate surges and growth; it can also be used to notice suspicious traffic patterns, like credential stuffing attacks.
- ⬆️ Uptime monitoring: many services offer simple tools to ping your websites and verify that expected content is there; this is a simple way, in lieu of fully featured UI automation tests, that you can verify your site is available to your end users.
- 🚨 Alerting: once you have tools in place to detect errors and anomalies, you’ll want an actual mechanism to alert you of the issue. Many tools, like PagerDuty, even provide complex scheduling tools to ensure that the burden of responding is spread fairly and that no one person is a single point of failure.
- 📊 Analytics: in addition to knowing when something is wrong with your system, you’ll also want to understand how people are using your system. We initially launched with a very simple Google Analytics implementation to let us see traffic, devices, and page views and have since introduced MixPanel to get more detailed insights.
- 💬 Customer Support: tools like Intercom give your users a way to reach out to the team directly if there are issues; this is not only useful for when your new system launches but can also be used during testing, as detailed below.
Test, Test, Test 🧪
So the new system is finally built and you’re pretty confident you’ve built the “right” thing, so you’re ready to launch, right? Not so fast! Even if you already have some test coverage, you’ll probably want to augment with some dedicated manual testing from folks besides you. This might look as follows:
- Test plans: before asking for other folks to hammer on your system, it often makes sense to start a spreadsheet and list out what areas and flows of the system absolutely need attention. A couple of months before launch, I created such a document to outline the various authentication, class enrollment, and membership enrollment flows I felt were critical to the success of the site.
- Bug bashing: at the recommendation of a former Runkeeper colleague, we organized a couple of hour-long bug bashes for the broader team to hammer on our website and log change request tickets; this allowed me to share the burden of quality assurance with my non-engineering teammates and to keep a log of outstanding issues. Then, I worked with my founders to identify which tickets to prioritize addressing before launch.
- UAT and beta testing: depending on what your stakeholder situation is like, you may want dedicated User Acceptance Test sessions. Because Ompractice is a small, scrappy company, we instead opted to do a less formal beta testing period where we launched the new site behind a password and invited our teachers, our top twenty or so power users, and several dozen volunteers from our newsletter to use the site before we revealed it to the world. In doing so, we identified issues that wouldn’t emerge without more concurrent users and gave some of our long-time students a chance to give us early feedback.
Prepare for the Data Migration 🛢
At this point, the new system is built and well-tested and you’re ready to bring it to life, but there’s one more critical piece still missing: the data. Because you’ve rewritten a system, chances are that there’s data you need to migrate from the old system to the new one, and chances are you’ll need to do it reliably and securely.
I’ve done several data migrations in my career, from authentication systems with millions of users to ecommerce systems with millions of dollars in revenue, and the data migration is certainly one of the most tedious and nerve-wracking parts. Fortunately, there’s a few techniques to make it easier and less error-prone:
- 🧪 Test your approaches: before dumping data into the production system, first test out your mechanism in a local or hosted development environment. Are you using SQL queries directly on your database? Are you running scripts to handle transforming and exporting the data? Test these mechanisms with dummy data in non-production systems first.
- ✋ Only migrate the data you need: not all data needs to be ported, or at least not ported right away. For example, while migrating to a new ecommerce system, you might want to migrate the archived orders last (or not at all) and focus only on unfulfilled orders or orders still in their return window. In the case of Ompractice, we punted on migrating past class attendance data for the time being.
- 🪣 Batch your data: don’t migrate all the data all at once! Understand the load that your system can handle and chunk the data you’re migrating into batches that fall reasonably below this max load. For example, I migrated Ompractice users to the new system in about forty batches.
- ☕️ Start your migration early: the data does not need to be migrated all at once, and oftentimes, it does not all need to be migrated during the actual cutover. For example, I migrated most Ompractice users a month before our launch date. Then, a week before launch, I migrated the new users who had joined in the prior few weeks, and finally I migrated the last handful of newly registered users during the cutover itself. Of course, the timing will depend on the data’s mutability: migrate data that is unlikely to mutate as early as you can and save the newest or most mutable data until right before or during the cutover.
Plan and Execute the Cutover 🎬
At this point, you have your new system and your migrated data all ready to go. The last step is to plan the cutover to the new system and then to actually do it. Some tips to make this part easier:
- ✅ Make a checklist: you’ll have enough to worry about during the cutover, so reduce your cognitive load by making a checklist you can follow: what steps need to happen, in what order do they need to happen, and who can do them? Which leads me to my next tip…
- 🙋♀️ Recruit help: even if you engineered the system alone, chances are that you don’t need to launch the system alone. Recruit other folks in your company to hop onto a call and take on some of the cutover tasks, within reason. At Ompractice, it was unreasonable for me to expect anyone else to take on data migration activities, so I kept those to myself and instead offloaded configuration and testing tasks. My teammates gladly took on tasks like updating links and turning pages off in WordPress and testing the new site, and it greatly reduced my own stress.
- 🕰 Choose your downtime: oftentimes, cutovers involve a bit of downtime, so choose a date and time that will have the least impact to your business. At ASICS, we migrated our US ecommerce site at 2AM in the morning. At Ompractice, the timing was a bit easier: we found a four-hour gap in our class schedule on a Monday afternoon and did the cutover then.
- 🥊 Roll with the punches: things don’t always go as planned, and that’s okay! One of our first cutover steps was to turn on “maintenance mode” in our WordPress site, and to our frustration, the plugin we used for this simply did not work. Because we hadn’t tested this one piece before the cutover, we didn’t find out until we really needed it, but we all took deep breaths and simply looked for an alternative plugin. Five minutes later, we found an alternative and were back on track and the rest of the cutover proceeded smoothly.
I can’t emphasize enough how important it is to plan your cutover upfront, so let me try with a very personal anecdote. About thirty minutes into our cutover in March 2022, I received a call from my vet; she told me that my sick cat’s x-rays revealed some lumps and she suspected they were cancer. She made it very clear that we could do some more tests but the prognosis wasn’t looking good. This was devastating personal news to receive in the middle of a cutover for which I had prepared for over a year.
Luckily, I could finish my own tasks pretty easily because I was simply following a checklist and because the rest of the Ompractice team had already graciously stepped up to complete the rest of the configuration and testing tasks. By planning my own tasks upfront and by sharing the burden with others, I set myself up to wrap up the cutover early and cleanly and spend the rest of the evening focused fully on my sick cat.

Celebrate 🥳
At last, you did it! The new system is live! But you’ve only just begun: the rewrite was just a starting point, and now you have a fresh new project upon which to build new things.
The rewrite was just a starting point, and now you have a fresh new project upon which to build new things.
Still, take a pause and appreciate the milestone. Chances are, you spent months of time and energy to get to this point, and that’s something worth celebrating.
You probably (hopefully) had help along the way – from your colleagues and network and users – so take a few minutes to thank them personally and specifically. Also, treat yourself and plan some time off in the not-too-distant future. Personally, I took a couple days off a few days after the cutover to spend some time with my cat and then started planning a much longer summer vacation to visit family. Figure out what works to rejuvenate you and make it happen!
Lastly, if you were stressed, find some time to relax. I hear yoga and meditation are great ways to do just that 😉, and Ompractice has a full schedule with a variety of offerings: https://app.ompractice.com/schedule